
What is Streaming ETL?
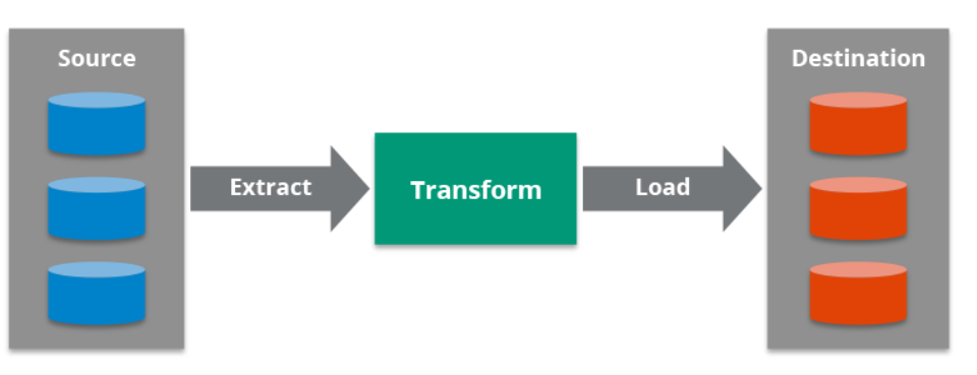
Streaming ETL is defined as the migration and processing of real-time data from one point of contact to another. ETL is an abbreviation for the Database functions Extract, Transform, Load where Extract refers to the collation of data from a variety of disparate sources. Transformation specifies the processes that can be performed on that data and Loading talks about sending the processed data to a destination, preferably a Data Warehouse or a database. In Streaming ETL, Extract, Transform, and Load takes place against streaming data in real-time in a Stream Processing platform. Generally, the originating system for Streaming Data is referred to as a source while the destination is called a sink.
Streaming ETL is becoming increasingly more important in today’s landscape since technologies like Online Retail, the Internet of Things, and Banking Transactions are generating massive amounts of data at a frightening pace.
Key Factors Influencing the Importance of Streaming ETL
Here are the key factors that have a pivotal role in influencing the importance of Streaming ETL for Modern Data Pipelines:
- Cloud-native Services: For Data Engineering teams, Cloud-native services are recommended since they can provide supremely better just-in-time scaling. This helps tackle fluid real-time data sources so that they don’t have to over-allocate services or be worried about downtime.
- Affordability: There are two aspects of affordability to keep in mind- resource efficiency and human efficiency. Today’s modern real-time solutions are easy to manage and intuitive. This means it requires less computing and headcount to deliver a speedy response that can be easily scaled as well.
- SQL Compatibility: SQL, continues to evolve despite being around for over half a century now. Adopting Structured Query Language for real-time Analytics is the most accessible and affordable choice going forward.
- Instant Insights: Streaming ETL provides you with the ability to scour, accumulate, and join data as it arrives from various disparate sources, detect anomalies in real-time and warn the right users wherever they consume their information.
- Low Data Operations: Real-time Data Pipelines mark a shift from complex data transformations to simple continuous transformations. If you want to carry out a lot of denormalization of data, schema management, or flattening of JSON code before data ingestion, then it is neither real-time nor modern
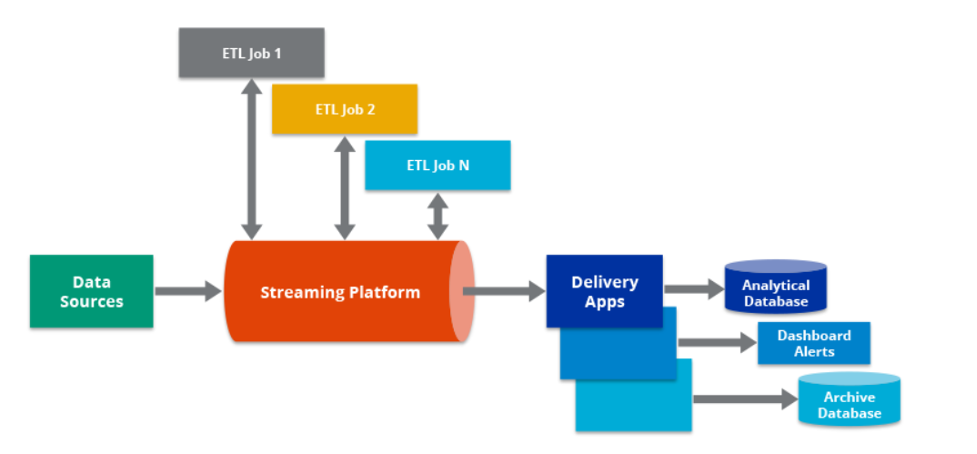
Understanding the Streaming ETL Architecture
In theory, Streaming ETL architecture bears resemblance to Traditional ETL architecture. At its inception, you have a data origin that feeds into a system that transforms and distills data from that source, and then the output can be delivered to a destination. When displayed in a pictorial format, the architecture usually has the origin to the left, the ETL driver in the center, and the sink on the right side.
In real-time Complex Event Processing ETL architectures, you also have sources to the left which can then proceed to the Complex Event Processing program. This Complex Event Processing platform can then serve as the backbone to Streaming ETL applications, among other sophisticated contiguous processes and applications. Here, the Event Processing application may pull data from the origin, or the origin might produce data directly to the Complex Event Processing application. After the completion of the Streaming ETL process, it may pass the data to the sink. Otherwise, the streaming ETL application might send a result back to the source on the left. Apart from this, it can also concurrently deliver data to other data repositories and applications.
Streaming ETL vs Batch ETL
Previously, ETL software was used to gather batches of data from a source system (schedule-based), transform it, and then load it to a Data Repository like Databases or Data Warehouses. Its impact started waning because various modern business environments cannot afford to wait for days for applications to tackle batches of data. They would have to respond to new data at the same time as the Data Generation.
These applications need Streaming ETL to function efficiently. Edge Computing, Fraud Detection, real-time Payment Processing, and Streaming Analytics are salient examples of applications that depend on Streaming ETL.
For instance, take a swindling detection application. When you swipe your credit card, the transaction data is migrated to or collated by the fraud application. The application can then be appended to the account data in a transform step with extra information about you. Next, Fraud Detection algorithms are applied that contain relevant information like the time of your most recent transaction. This checks if you’ve recently purchased from that store, and how your purchase stands vis-a-vis similar buying habits. Next, the application loads up the resulting denial or approval to the credit card reader. Banks can cut down on their swindling losses by thousands of millions of dollars every year simply by anchoring Event Processing ETL to carry out this process in real-time.
Understanding the Benefits of Stream Processing
With Complex Event Processing, you can rest assured that you will always have fresh data available since you are processing one event at a time in real-time. Complex Event Processing can also help you save the cost since you don’t have to run the operations on small servers. Complex Event Processing ensures a small amount of processing for every stream or piece of data in real-time.
Conclusion
This blog talks about the salient aspects of Streaming ETL and its importance in great detail. This includes the benefits, comparative edge over Batch ETL, and the primary factors that make it an integral component in the modern data stack.
Hevo Data is a No-code Data Pipeline that empowers you to integrate and load data 100+ Data Sources to the desired destination in absolute real-time. All in a seamless manner. Hevo houses a minimal learning curve. Hence, you can configure and get started with Hevo, all in a matter of a few minutes or clicks.







{kind=link}